What is it and why is it needed?
Last week, I spent some time writing prompts for classifying documents into a fixed set of classes based on their OCR text. I spent some time tweaking and experimenting with the prompt for the model to behave exactly how I wanted it to behave. But prompt tuning, for those who have tried it, knows how painfully daunting it is to make these models behave exactly how you’d like them to behave… that also consistently. This snippet from a YouTube video summarizes prompt engineering in a nutshell.
It took me some time to tune the prompt even for such a simple task. This is not the first time I have spent my mental sanity just to make these models follow my instructions. So, with frameworks like DSPy, which promise to algorithmically optimize LM prompts rather than relying on my brute force, intuition, and trial-and-error methods, I decided to give it a try. So without further ado, let’s dive right into it (it feels like I’m writing a script for a YouTube video, lol).
Building blocks [Signatures and Modules]
In DSPy, you need to write your input output expectation from LLM as dspy.Signatures. It is pretty similar to function signatures we write in python. Lets start off by writing a simple signature that defines the input and output for our use case.
import dspy
# set the LM
lm = dspy.OpenAI(
model="gpt-3.5-turbo",
)
dspy.settings.configure(lm=lm)
class DocClassificationSignature(dspy.Signature):
"""Classify doc into classes"""
document = dspy.InputField(desc="Doc data")
document_type = dspy.OutputField(
desc=f"Possible classes: invoice, bank statement, tax form, certificate of liability, other"
)
I deliberately wrote bad signature so that I could see how it got tuned over time. I could’ve speicified Doc as Document, Doc data as Document's OCR Data. After signature, we needed to define a dspy Module. A dspy module can have one or more dspy signatures. Taking analogy from pytorch, you can think of dspy signatures as nn.Linear that defines the input and output and dspy module as nn.Module.
class SimpleDocClassificationModule(dspy.Module):
def __init__(self):
super().__init__()
self.classify_doc = dspy.Predict(DocClassificationSignature)
def forward(self, document):
return self.classify_doc(document=document)
Lets see how this simple module works, I can invoke this module like this
document = """Lorem ipsum dolor sit amet, consectetur adipiscing elit. Aenean rutrum auctor turpis, ac pulvinar sapien pulvinar ac. Sed vehicula nunc ipsum, nec eleifend enim elementum et. Curabitur a odio vel lorem dictum pellentesque. Phasellus ac velit mauris. Cras congue eget quam nec euismod. Curabitur risus est, lobortis id nibh nec, lacinia aliquet purus. Sed ac elit gravida, imperdiet leo sit amet, facilisis ipsum. Praesent gravida, neque a elementum fermentum, ligula lacus imperdiet justo, quis pretium velit tellus ac est. Proin volutpat dui eget leo tincidunt, vitae mattis quam placerat. Curabitur et neque et dolor vulputate feugiat et sit amet massa."""
op = SimpleDocClassificationModule()(document)
print(op)
Prediction(
document_type='Other'
)
The module sucessfully predicted the right class for the text. Lets inspect the underlying LLM call it made to get the output
lm.inspect_history(n=1)
Classify doc into classes
---
Follow the following format.
Document: Doc data
Document Type: Possible classes: invoice, bank statement, tax form, certificate of liability, other
---
Document: Lorem ipsum dolor sit amet, consectetur adipiscing elit. Aenean rutrum auctor turpis, ac pulvinar sapien pulvinar ac. Sed vehicula nunc ipsum, nec eleifend enim elementum et. Curabitur a odio vel lorem dictum pellentesque. Phasellus ac velit mauris. Cras congue eget quam nec euismod. Curabitur risus est, lobortis id nibh nec, lacinia aliquet purus. Sed ac elit gravida, imperdiet leo sit amet, facilisis ipsum. Praesent gravida, neque a elementum fermentum, ligula lacus imperdiet justo, quis pretium velit tellus ac est. Proin volutpat dui eget leo tincidunt, vitae mattis quam placerat. Curabitur et neque et dolor vulputate feugiat et sit amet massa.
Document Type: Other
The Tuning
Dataset
To tune the prompt, I needed some examples to use as a training and test set. I resorted to doing what most current research in LLMs does: generating synthetic data from LLMs. Here is a short snippet I used:
SYSTEM_PROMPT = "You are a highly intelligent document generator that will generate a dummy ocr text for the provided document type. You will not generate any other text apart from the OCR Text"
classes = ["invoice", "bank statement", "tax form", "certificate of liability", "other"]
generated_texts = defaultdict(list)
for _class in classes:
# 10 examples per class
for _ in range(10):
completions = client.chat.completions.create(
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": f"Please generate dummy ocr text for document type: {_class}. Strictly give only the OCR value and no other text",
},
],
model="gpt-3.5-turbo",
)
generated_texts[_class].append(completions.choices[0].message.content)
df = pd.DataFrame(generated_texts)
In just under 5 minutes (including the time to write the above snippet), I had 50 document ocrs I could use to tune the prompt. What a wonderful era we are living in!
Now, let’s take the 50 samples we generated and prepare them in a format DSPy can consume. For this, we need to convert our data into a list of their data structure dspy.Example, i.e., (List['dspy.Example']). Then, just like any other supervised learning task, we need to split our dataset into training and testing sets. I chose a 60-40 split—not for any specific reason but just to see how much accuracy gain we can achieve with a small number of training samples. Here is the code to accomplish everything I just mentioned:
classes = df.columns.to_list()
dataset = []
for _class in classes:
for item in df[_class].to_list():
example = dspy.Example(document=item, document_type=_class).with_inputs("document")
dataset.append(example)
random.shuffle(dataset)
train_set = dataset[:30]
test_set = dataset[30:]
DSPy Optimizers (prev. Teleprompters)
Now lets take the above dataset we generated to tune the prompt using DSPy’s Optimizers(formerly known as teleprompters, which sounded pretty cool imo). As of this writing, they provide 8 optimizers. They have a good starter guide regarding which optimizer to use in which cases. Some optimizers add few-shot examples to the prompt, while others optimize the initial prompt, and some do both at the same time.
I’ll be using MIPRO optimizer that will optimize the initial prompt given as well as generate few shot examples. If you want a deeper understanding of how this optimizer works under the hood, DSPy has good deep dive article about how they optimize the prompt and how they generate few shot examples.
But like any other traditional ML training techniques, we need to first define our evaluation metric/criteria. DSPy allows us to define our own custom function, which will receive ground truth and prediction. We can write any logic of our own and return a bool. For my use case, I used fuzzy matching to check the match between my ground truth and prediction.
from rapidfuzz import fuzz
def is_similar(gold:dspy.Example, pred:dspy.Example, trace=None):
gt = gold.document_type
prediction = pred.document_type
score = fuzz.partial_ratio(gt, prediction)
return score >= 80
Now, I’ll create the optimizer with the metric function I just defined.
from dspy.teleprompt import MIPRO
teleprompter = MIPRO(
metric=is_similar,
verbose=True
)
Finally, we can start the tunining process by calling teleprompter.compile() with necessary arguments.
kwargs = dict(num_threads=4, display_progress=True, display_table=0)
optimized_module = teleprompter.compile(
SimpleDocClassificationModule(),
trainset=train_set,
num_trials=2,
max_bootstrapped_demos=3,
max_labeled_demos=3,
eval_kwargs=kwargs,
)
Since the optimizers use LLMs internally to tune the prompt and generate few-shot examples, teleprompter.compile() will first provide you with an estimate of the number of LLM calls it will make based on your dataset and the optimizer’s parameters that you’ve set. It’s important to carefully review this because it’s easy to misconfigure a few settings, leading the optimizer to send an astronomically high number of requests to your LLM.
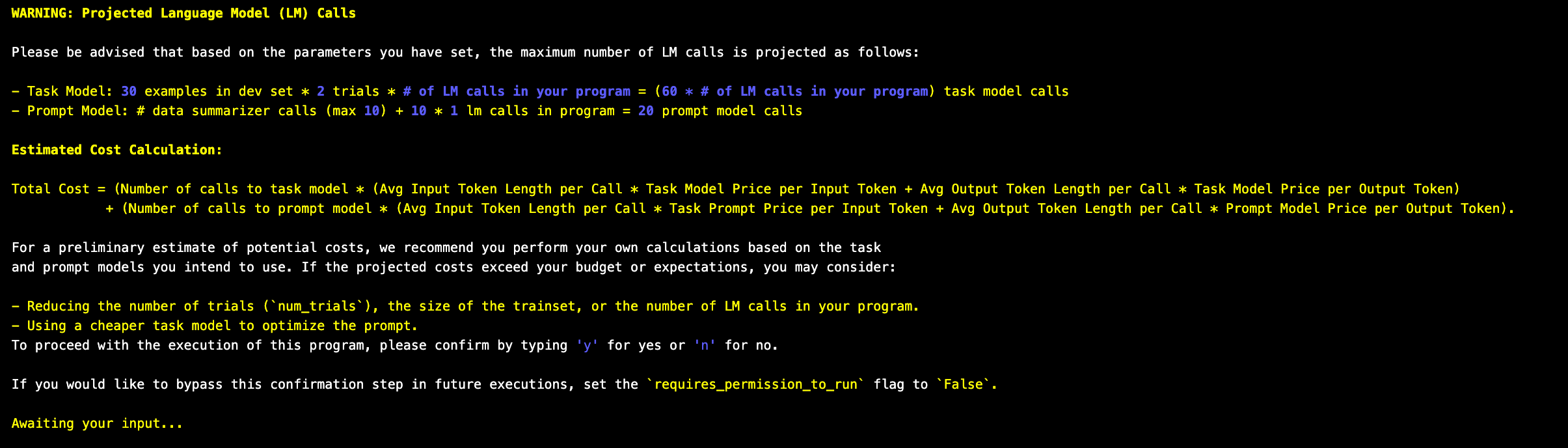
So for my use case, there will be ~80 LLM calls. That in itself feels like a pretty large number of requests for such a simple usecase and small dataset. I’m a bit skeptical about the scalability of this approach as the dataset size grows. However, it is still a much more economically viable option compared to fine-tuning the model itself.
Once the tuning begins, we can observe how the metrics change after each iteration. Similarly with the debug mode, we can also view the prompts that are getting executed under the hood for tuning.
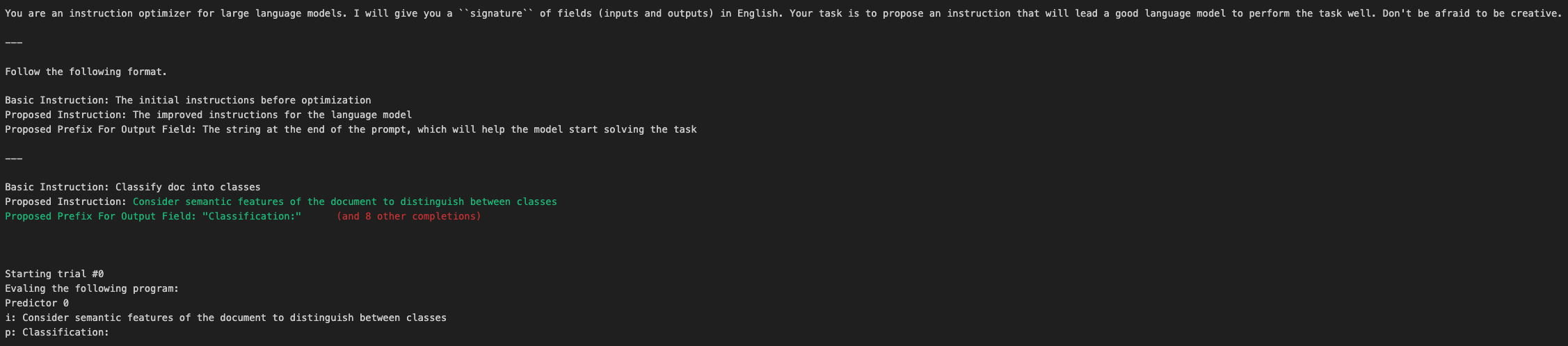
Finally, once the tuning is completed, we can take a look into the optimized program.
print(optimized_module)
classify_doc = Predict(StringSignature(document -> document_type
instructions='Consider semantic features of the document to distinguish between classes'
document = Field(annotation=str required=True json_schema_extra={'desc': 'Doc data', '__dspy_field_type': 'input', 'prefix': 'Document:'})
document_type = Field(annotation=str required=True json_schema_extra={'desc': 'Possible classes: invoice, bank statement, tax form, certificate of liability, other', '__dspy_field_type': 'output', 'prefix': 'Classification:'})
))
Just prompting the module doesn’t show the few shot examples it has generated. For that, lets predict on the document we defined earlier and inspect the full LM call history to see the optimized prompt and the few shot examples that the optimizer generated.
document = """Lorem ipsum dolor sit amet, consectetur adipiscing elit. Aenean rutrum auctor turpis, ac pulvinar sapien pulvinar ac. Sed vehicula nunc ipsum, nec eleifend enim elementum et. Curabitur a odio vel lorem dictum pellentesque. Phasellus ac velit mauris. Cras congue eget quam nec euismod. Curabitur risus est, lobortis id nibh nec, lacinia aliquet purus. Sed ac elit gravida, imperdiet leo sit amet, facilisis ipsum. Praesent gravida, neque a elementum fermentum, ligula lacus imperdiet justo, quis pretium velit tellus ac est. Proin volutpat dui eget leo tincidunt, vitae mattis quam placerat. Curabitur et neque et dolor vulputate feugiat et sit amet massa."""
op = optimized_module(document)
lm.inspect_history(n=1)
Consider semantic features of the document to distinguish between classes
---
Follow the following format.
Document: Doc data
Classification: Possible classes: invoice, bank statement, tax form, certificate of liability, other
---
Document: 3047-A Copy C Remove the top KID for your records. SECTION CORPDESCRIPTION $3,719.25 Name: John Doe Address: 123 Main Street, Anytown, USA Account Number: 987654321 FED ID # 12-3456789 Code: ABC123 Do not write or staple in this space 10/15 O Tax year 16 5680 2,347.89 $ Taxpayer must sign and date in blue or black ink, and enter the above information in blue or black ink, then mail to: Department of Revenue, P.O. Box 123, Anytown, USA Income: S Total tax withheld: P KP Total Payments Total from Phaelbe6 Elected to apply to next your 134.65 Underpayment penalty T 2020 Luxury Tax 0.00 48.90 $ Overpaid Refund $2,701.19 Heike Beste This is your tax liability for the tax year shown at the top of the form. Sign and return to the address shown above.
Classification: tax form
---
Document: OCR Text: Invoice Number: 483921 Date: 09/27/2022 Customer: John Doe Total Amount: $350.00
Classification: invoice
---
Document: 0498-5672-3498 Name: John Smith SSN: 123-45-6789 Total income: $50,000 Deductions: $10,000 Taxable income: $40,000 Tax owed: $7,000 Please consult your tax advisor for accurate information.
Classification: tax form
---
Document: Lorem ipsum dolor sit amet, consectetur adipiscing elit. Aenean rutrum auctor turpis, ac pulvinar sapien pulvinar ac. Sed vehicula nunc ipsum, nec eleifend enim elementum et. Curabitur a odio vel lorem dictum pellentesque. Phasellus ac velit mauris. Cras congue eget quam nec euismod. Curabitur risus est, lobortis id nibh nec, lacinia aliquet purus. Sed ac elit gravida, imperdiet leo sit amet, facilisis ipsum. Praesent gravida, neque a elementum fermentum, ligula lacus imperdiet justo, quis pretium velit tellus ac est. Proin volutpat dui eget leo tincidunt, vitae mattis quam placerat. Curabitur et neque et dolor vulputate feugiat et sit amet massa.
Classification: other
Evaluation
Now that we have an optimized module, we can use dspy.evaluate.Evaluate to evalute the performance. It’s also pretty straightforward to use. We just need to define the evaluator with the desired test set and other configurations. Then, we can simply pass the module and metric function to the evaluator to get the metrics.
Lets first evaluate our previous module (before optimization).
eval_score_old = evaluator(SimpleDocClassificationModule(), metric=is_similar)
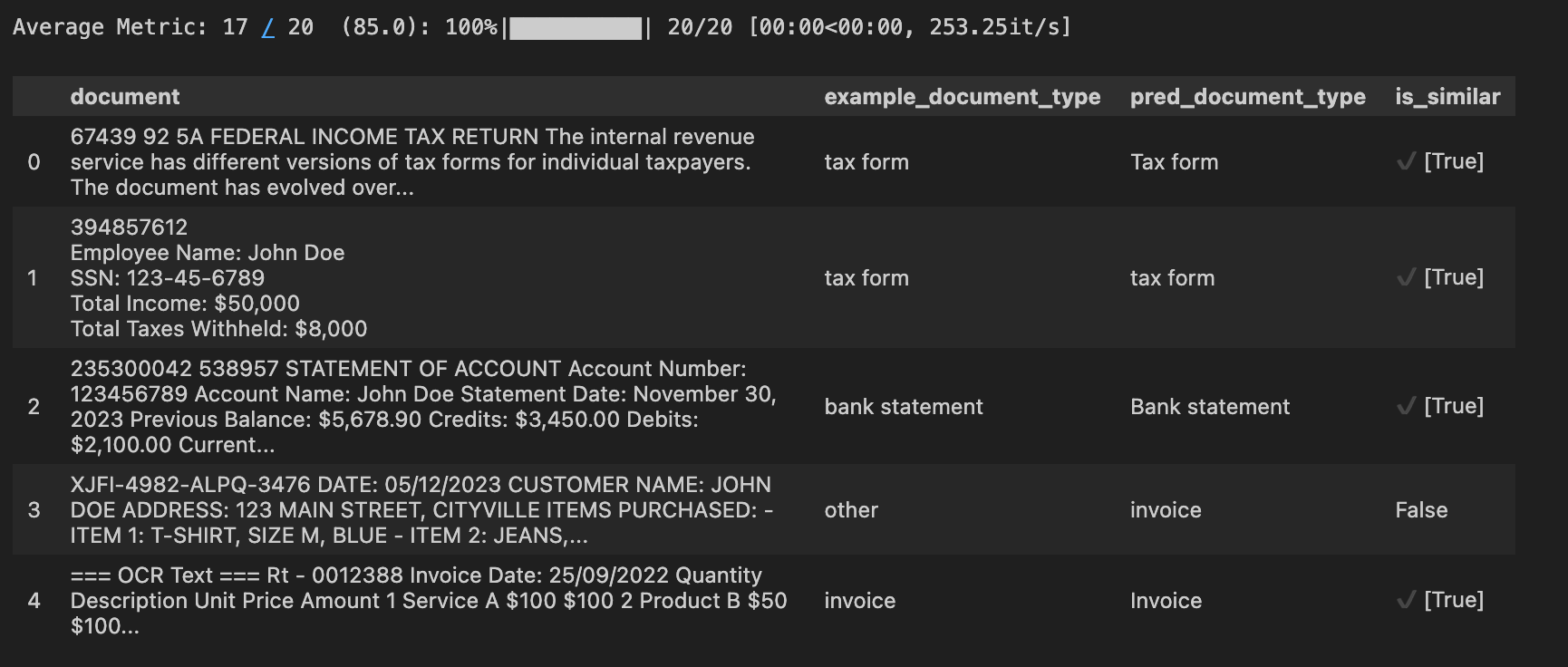
We can see that with our initial module, the LLM correctly predicted 17/20 (85%), which is surprisingly good for such bad prompt.
Now, lets see how our optimized module performed:
eval_score_new = evaluator(optimized_module, metric=is_similar)
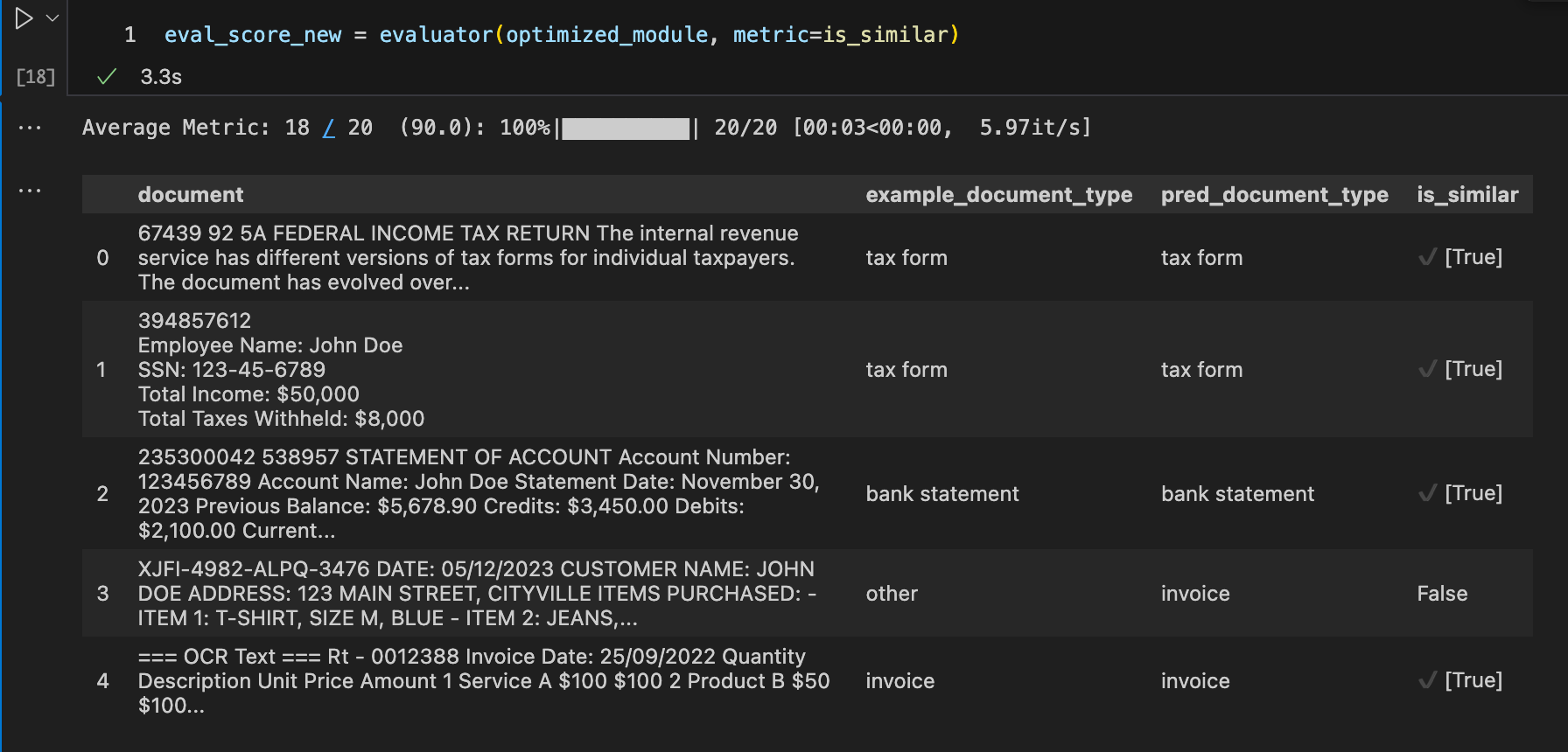
Voila, the metrics improved from 85% to 90% (though it made just one more correct prediction—aah, statistics, how many ways can people find to manipulate you! :P). Though it’s not a huge improvement, please note that the data was dummy data. We improved the prompt and added a few-shot example in an algorithmic manner rather than begging the LLM to respond correctly, which I feel is pretty neat!